 Blog Home
Blog Home
Apache Spark เรียกสั้นๆกันว่า Spark เป็นหนึ่งในเครื่องมือ Big Data ที่ได้รับความนิยมสูง และยังเป็นแพลตฟอร์มหนึ่งที่เป็น Open Source เปิดให้ทุกคนเข้าไปแก้ไข ดัดแปลง และพัฒนาต่อได้
Serverless คือแนวทางการสร้างระบบซอฟร์แวร์ ที่ลูกค้าไม่ต้องดูแลเซิร์ฟเวอร์ตามชื่อ (Serverless) ประโยชน์ของระบบ Serverless คือ นอกจากลูกค้าจะไม่ต้องลงทุนสร้างโครงสร้างพื้นฐาน (Infrastructure) เอง ก็สามารถใช้งานจากผู้ให้บริการ Cloud อย่าง Google Cloud Platform, Amazon Web Service หรือ Microsoft Azure ได้
บริการน้องใหม่ของ Google Cloud ได้ทำการนำ Spark มาทำเป็นระบบ Serverless ได้สำเร็จ โดยมีชื่อว่า Dataproc Serverless และในบทความนี้ เราจะมาทำความรู้จักกับ Dataproc Serverless กัน
Dataproc Serverless คืออะไร
Dataproc Serverless เป็นบริการใหม่จาก Google Cloud ที่ทำให้สามารถใช้ Apache Spark แบบ Serverless ได้ โดยที่ไม่จำเป็นต้องสร้างหรือจัดการโครงสร้างพื้นฐานเอง และจ่ายตามเวลาที่รันเท่านั้น ไม่จำเป็นต้องจ่ายเงินเป็นรายชั่วโมงอีกต่อไป
การเริ่มใช้งานก็ง่ายๆ เพียงแค่ระบุ workload ที่เราต้องการ และกดส่งค่าไป Dataproc Serverless ก็จะทำการสร้างโครงสร้างพื้นฐาน และสามารถปรับขนาดเซิฟเวอร์เพิ่มหรือลดขนาดลงเองตามความเหมาะสมที่ตั้งไว้
ยกตัวอย่างเพิ่มเติมสำหรับคนที่ยังไม่ค่อยเข้าใจคำว่า Serverless สมมติว่ามีคนเข้าเว็บไซต์ CloudHM มากขึ้น ส่งผลให้มีการใช้งาน CPU เพิ่มขึ้น บริการที่เป็น Serverless จะทำการปรับเพิ่มขนาด CPU ให้ตามค่าที่ถูกตั้งไว้เพื่อรองรับการใช้งานที่มากขึ้น และปรับขนาดลดลงเมื่อจำนวนคนเข้าน้อยลง
แนวคิดนี้เองที่เพิ่มความยืดหยุ่นในการรันอะไรหลายอย่าง รวมถึง Apache Spark สำหรับบริษัทที่ต้องทำการสำรวจข้อมูลเบื้องต้น, ทำกระบวนการ ETL, ทำ Analytics หรือ สร้างโมเดลด้าน Data Science ของ Big Data ก็สามารถใช้ประโยชน์จากจุดนี้ได้
จุดเด่นของ Dataproc Serverless
จุดเด่นหลักๆของ Dataproc Serverless คือ เป็นบริการแบบ Serverless Spark ซึ่งถือเป็นบริการแบบนี้บริการแรก จากผู้ให้บริการ Cloud เจ้าใหญ่ ช่วยให้เราสามารถเขียนแอปพลิเคชั่น Pipeline ที่ปรับขนาดเซิร์ฟเวอร์ได้อัตโนมัติ
นอกจากนี้ ระบบของ Google Cloud ยังเชื่อมกันหมด ทำให้ใช้งาน Dataproc Serverless จากบริการหลักอื่น ๆ ได้เลยภายในไม่กี่คลิก เช่น BigQuery บริการ Data Warehouse ที่เป็น Serverless รองรับข้อมูลขนาดใหญ่ได้, Vertex AI บริการการทำ Machine Learning ตั้งแต่ต้นจนจบ และ Dataplex บริการที่ช่วยจัดการแบบศูนย์กลาง ควบคุม และการทำ Data Governance
Dataproc Serverless มีเครื่องมือที่มีใน Spark ทั้งหมด สามารถใช้งานได้ตั้งแต่ Pyspark, Spark SQL, Spark R หรือ Spark Java/Scala
ตัวอย่างการใช้งาน Dataproc Serverless โดย OpenX
OpenX เป็นเครื่องมือจัดการระบบโฆษณาแบบ Open source ที่ใหญ่ที่สุดที่นำ Dataproc Serverless เข้ามาตัดปัญหาในการใช้งาน MapReduce Pipeline ที่ต้องทำงานหลาย jobs พร้อมๆกัน และมักต้องเพิ่มขนาด cluster จัดการการสเกลโดยอัตโนมัติอยู่บ่อยครั้ง และสร้าง cluster ใหม่เพื่ออัพเกรดประสิทธิภาพในการใช้งาน
Dataproc Serverless ช่วยทำให้เราสามารถโฟกัสกับ jobs ที่ต้องรันได้มากขึ้น โดยไม่ต้องกังวัลกับการจัดการทรัพยากรหรือโครงสร้างพื้นฐาน นอกจากนี้ยังเพิ่มประสิทธิภาพในการทำงานของทีม, ลดค่าใช้จ่ายในการสร้าง / ดูแลรักษา cluster เพื่อให้ใช้งานได้เต็มที่ในราคาที่เหมาะสม
ในอดีต ทีม OpenX รัน Data Pipeline รวมกับ job แบบ batch ทุกชั่วโมง ด้วยข้อมูลที่เข้ามา (input) ขนาดสูงสุดถึง 2.8 TB พอมีบริการ Dataproc Serverless ทำให้ OpenX สร้าง Data Pipeline ใหม่ขึ้นมาตามรูปด้านล่าง
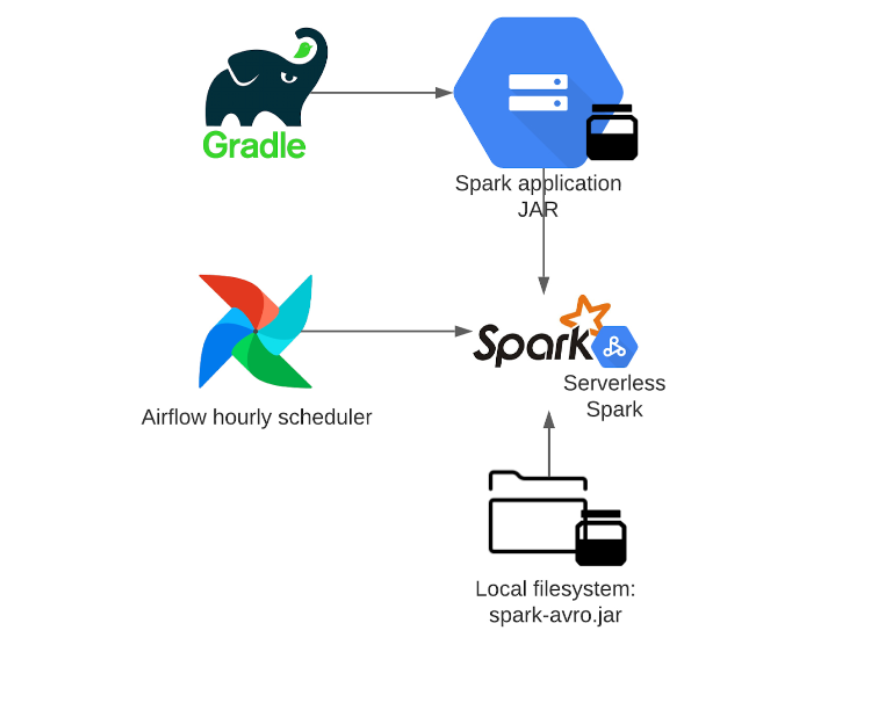
Dataproc serverless สามารถรัน job แบบ batch โดยอิงจาก Airflow ซึ่งจะทำการรันทุกชั่วโมง และตัว Dataproc serverless จะดึงไฟล์ Spark JAR มาจาก Google Cloud Storage ผ่านทาง Gradle และเชื่อมต่อกับระบบไฟล์ภายในเครื่องเซิร์ฟเวอร์ (Local filesystem) อีกด้วย ทำให้ Data Pipeline บน OpenX สามารถรันโดยไม่ต้องมีคนคอยเพิ่มทรัพยากร สเกลขึ้นลงเองอีกต่อไป
หากองค์กรของคุณกำลังตามหาระบบและบริการที่รองรับการเติบโตขององค์กร หรือต้องการที่ปรึกษาด้านเทคโนโลยีเกี่ยวกับ Data และ Google Cloud สามารถติดต่อพูดคุยกับทีมงาน CloudHM ได้เลยนะคะ
สำหรับในโอกาสหน้า เราจะหาบริการที่น่าสนใจมาเล่าให้ฟังกันอีกนะคะ
https://cloud.google.com/dataproc-serverless/docs
— Cloud HM