 Blog Home
Blog Home
ในยุคนี้ เทคโนโลยีที่ได้รับความนิยมและผู้คนพูดถึงไม่น้อย คงต้องยกให้ Artificial Intelligence หรือ AI ซึ่งบริษัท Nvidia ได้กำไรมหาศาลจากการขายการ์จอหรือ Graphic card ที่มีหน่วยประมวลผลจาก GPU ที่มีความสามารถในการใช้งานได้หลากหลาย รวมถึงเรื่อง AI ส่งผลให้บริษัทชั้นนำหลายๆ แห่งต้องการ GPU ที่มีพลังในการประมวลผลด้าน AI เพื่อนำมาวิจัยและพัฒนา AI ของตัวเอง เพื่อแข่งขันกับบริษัทอื่นๆ ในอุตสาหกรรมเดียวกัน ต่อไปเราจะมาดูกันว่า GPU ที่เป็นหัวใจสำคัญของ AI นั้นเป็นอย่างไร
GPU คืออะไร?
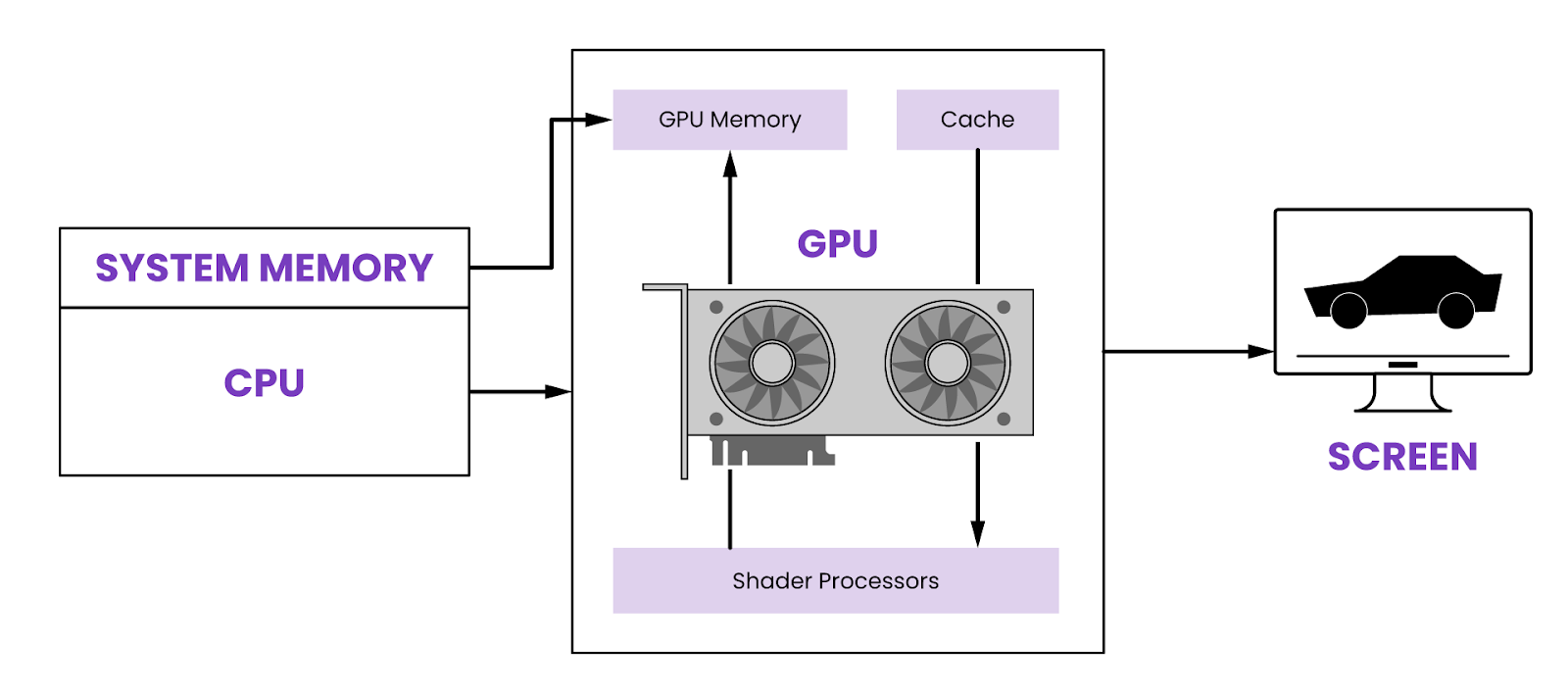
Image source https://www.weka.io/learn/guide/gpu/what-is-a-gpu/
Graphics Processing Unit หรือ GPU เป็นหน่วยประมวลผลกราฟิกที่ถูกออกแบบมาเพื่อช่วยในการ render กราฟิก โดยจุดประสงค์ดั้งเดิมใช้กับงาน 3D model เป็นหลัก ต่อมา GPU ถูกพัฒนาให้มีประสิทธิภาพมากขึ้น สามารถ render ภาพหรือวิดีโอได้สมจริงยิ่งขึ้น สามารถนำไปทำ Machine Learning หรือใช้ในการเทรน AI ซึ่งกำลังเป็นที่นิยมมากขึ้นในปัจจุบันมี Core ประเภทต่าง ๆ ที่เหมาะสมกับการทำงานที่แตกต่างกัน ได้แก่
CUDA Core
Compute Unified Device Architecture หรือ CUDA เป็น Architecture รูปแบบหนึ่งที่มีการประมวลผลแบบ Parallel ที่สามารถประมวลผลหลายๆ task พร้อมกันได้ ซึ่งถูกนำมาใช้ใน GPU เป็นครั้งแรกโดย Nvidia เมื่อปี 2006 เรียกว่า CUDA core
- ฟังก์ชัน: CUDA Core ถูกออกแบบมาให้ใช้งานในการคำนวณทางคณิตศาสตร์เชิงขนาด (Scalar Operation) เช่น บวก ลบ คูณ หาร จำนวนเต็ม
- Use Case: เหมาะสำหรับงานที่ประมวลแบบ Parallel ทั่วไป เช่น render โมเดล 2D, 3D ตัดต่อ Video หรือ Gaming
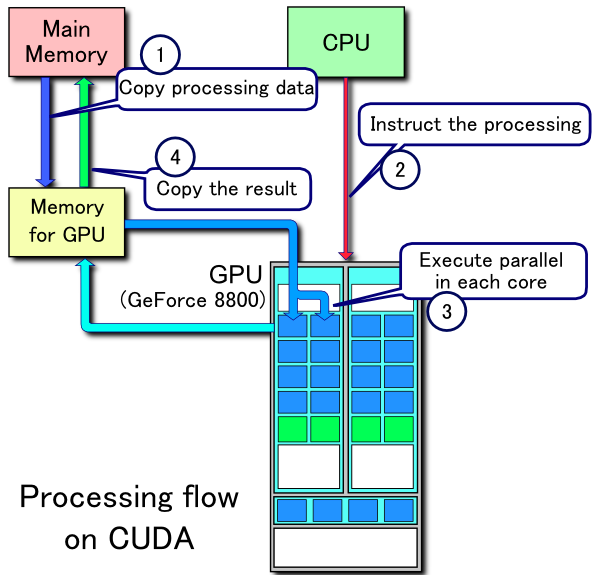
Image source https://www.digitalocean.com/community/tutorials/understanding-tensor-cores
Tensor Core
Tensor Core เป็นหน่วยประมวลผลที่ถูกพัฒนาขึ้นมาให้สามารถประมวลได้รวดเร็วยิ่งขึ้นด้วยการทำ Matrix Multiplication มีตั้งแต่ Rank 0 ถึง Rank 4 (0 ไปจนถึง 3 มิติ) ซึ่งเป็นขั้นกว่าของ Scalar ที่ถูกจำกัดอยู่แค่เชิงขนาดซึ่งไม่มีมิติทำให้ประมวลผลช้ากว่าหลายเท่าตัว Tensor Core ถูกใช้งานครั้งแรกเมื่อปี 2017 ใน Graphic Card ของ Nvidia ที่เป็น Volta Architecture
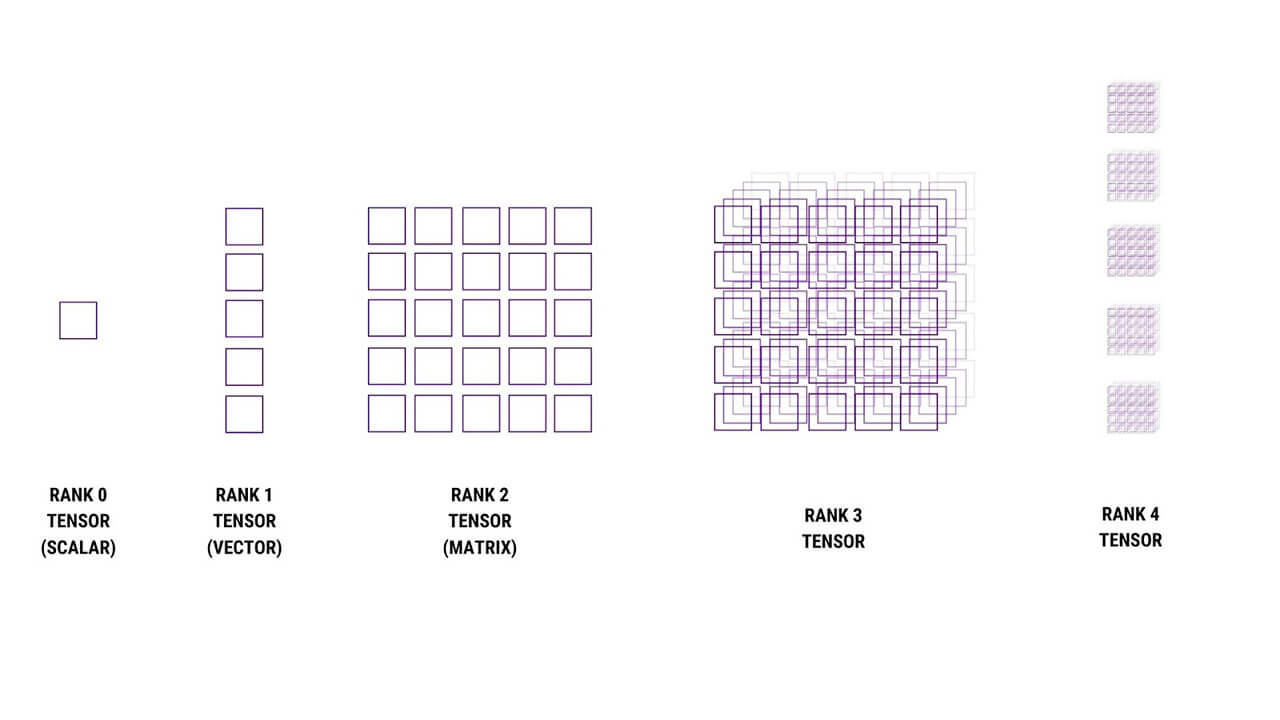
Image source https://www.techcenturion.com/tensor-cores/
- ฟังก์ชัน: เมื่อเทียบกับ CUDA core ที่สามารถทำงานได้ 1 operation ต่อ 1 Clock Cycle ส่วน Tensor Core สามารถทำได้หลาย Operations ต่อ 1 Clock Cycle
- Use Case: เหมาะสำหรับการเทรนโมเดล AI หรือทำ Machine learning โดยเฉพาะ Deep learning ที่ต้องใช้การประมวลผลจำนวนมาก
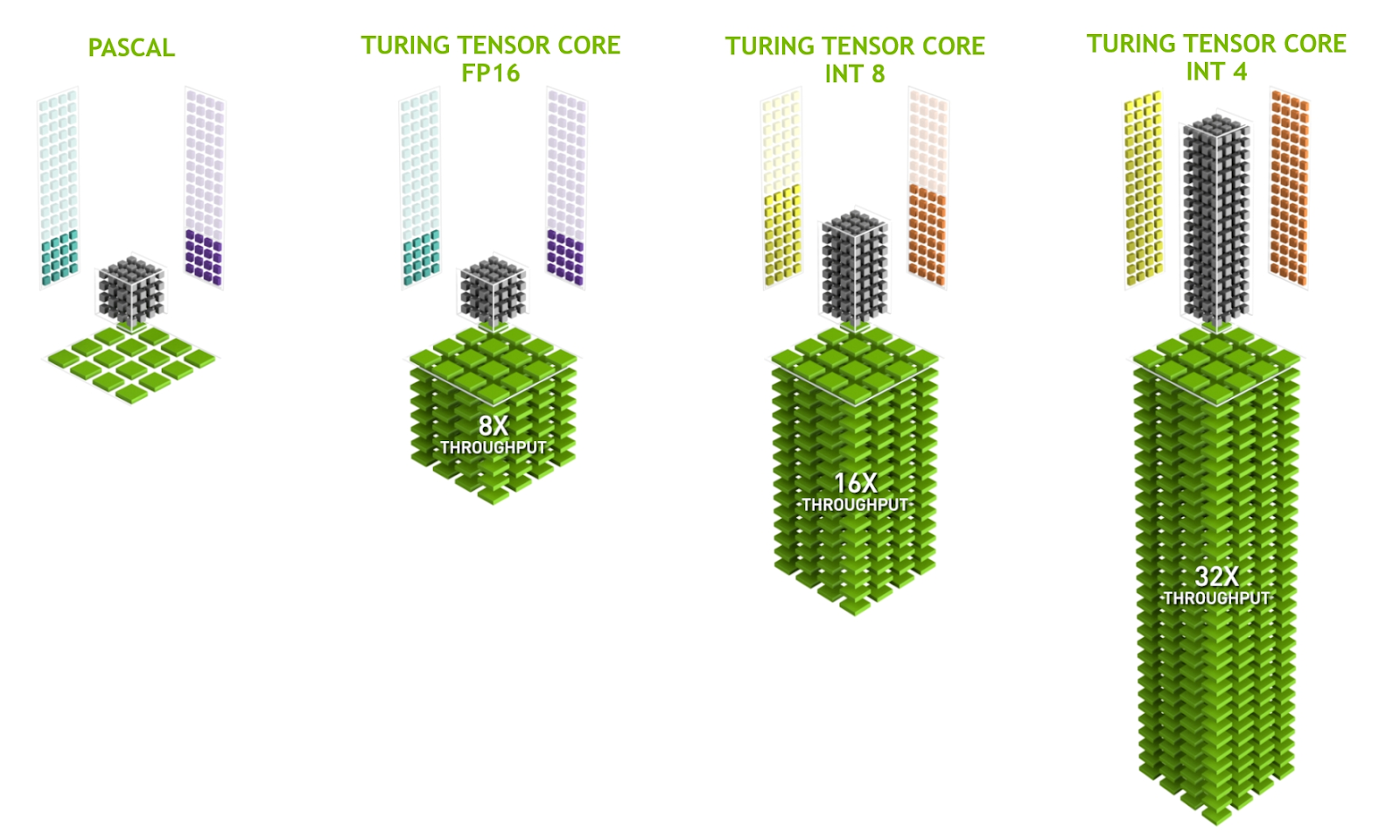
Image Source https://developer.nvidia.com/blog/nvidia-turing-architecture-in-depth/
สามารถรับชมการอธิบาย Tensor Core เพิ่มเติมได้ ที่นี่
Ray-Tracing Cores (RT Core)
Ray-tracing เป็นเทคโนโลยีที่ถูกนำมาใช้ครั้งแรกใน Graphic Card ที่เป็น Turing Architecture เมื่อปี 2018 ซึ่งใช้ RT Core ซึ่งนับว่าเป็นรุ่นถัดมาที่ใช้ Tensor Core (2nd generation) สามารถ render ในส่วนของแสงและเงาให้กับโมเดลแบบ 3D ทั้งแบบภาพนิ่งหรือภาพเคลื่อนไหวให้มีความสมจริงมากยิ่งขึ้นแบบ Real Time โดยจะคำนวณจากจุดที่กำเนิดแสง ระยะทางจากจุดกำเนิดแสงไปยังวัตถุ เงาที่เกิดขึ้น และ render ภาพจากมุมมองของเราออกมา
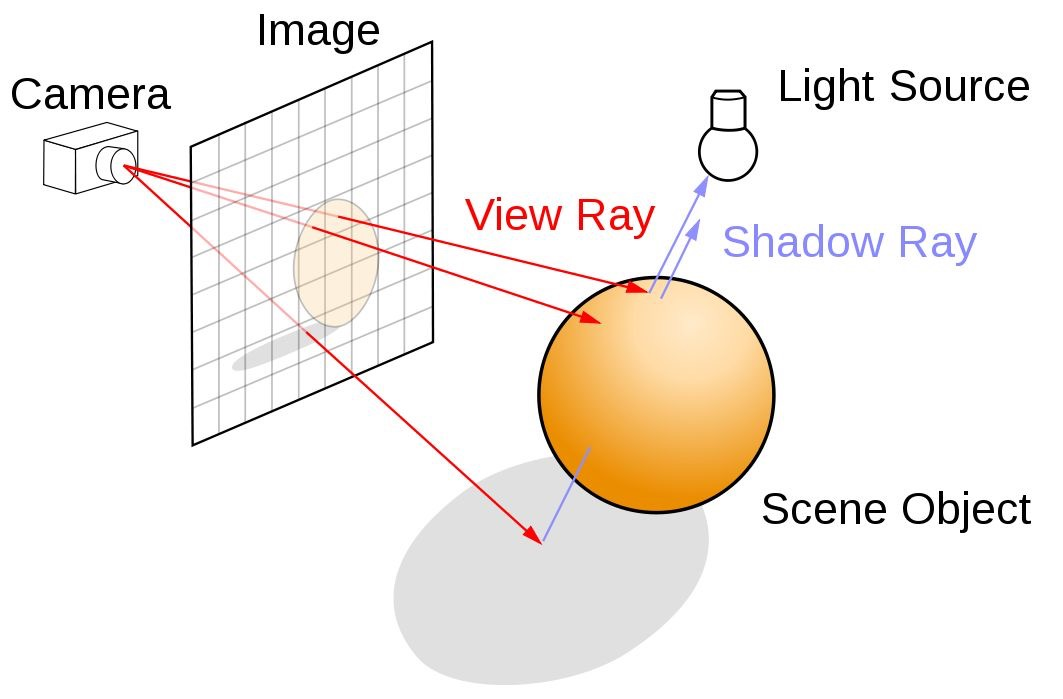
Image source https://developer.nvidia.com/discover/ray-tracing
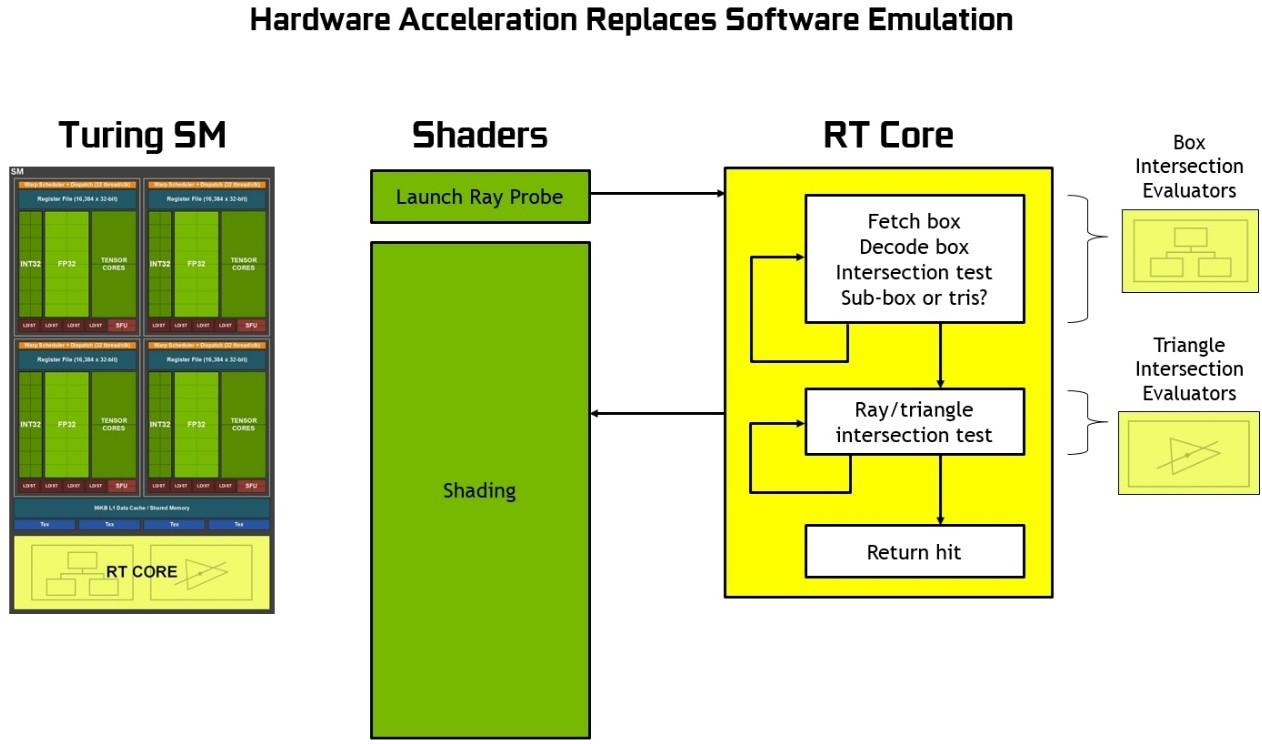
Image Source https://developer.nvidia.com/blog/nvidia-turing-architecture-in-depth/
- ฟังก์ชัน: RT Core ถูกออกแบบมาเพื่อปรับปรุงคุณภาพของแสงและเงา ซึ่งทำงานร่วมกับ Tensor Core เพื่อการประมวลที่รวดเร็ว
- Use Case: เหมาะสำหรับการ render กราฟิกของแสงและเงาที่มีความสมจริงในเกมหรือโมเดลต่างๆ

Image source https://www.ionos.co.uk/digitalguide/fileadmin/_processed_/d/2/csm_raytracing_en_f0ae9ce28f.webp
{kind=link}
เราสามารถเปรียบเทียบ Core แต่ละประเภทได้ตามตารางด้านล่าง
| คุณสมบัติ | CUDA Core | Tensor Core | RT Core |
| ฟังก์ชันการประมวลผล | ประมวลผลแบบ Parallel | ประมวลผลแบบ Matrix Multiplication | ใช้เทคโนโลยี Ray Tracing |
| Use Case | Render 2D หรือ 3D โมเดล, Gaming, การประมวลผลทั่วไป | AI Training, Deep Learning | Gaming, Video Enhancement |
| ประสิทธิภาพ | ปานกลาง | สูง | สูง (โดยเฉพาะงานวิดีโอและเกม) |
ต่อมาในปี 2020 ทาง Nvidia ได้เปิดตัว Graphic Card ที่ใช้ Ampere Architecture ซึ่งเป็น 3rd Generation ที่ใช้ Tensor Core หลักๆ ในรุ่นนี้ได้เพิ่มประสิทธิภาพในการประมวลผลและการเทรน AI
Hopper Architecture
ในปี 2022 ทาง Nvidia ได้เปิดตัว Graphic Card ที่ใช้ Hopper Architecture ซึ่งเป็น 4th Generation ได้ใช้เทคโนโลยี NVIDIA® Transformer Engine ที่สามารถลดการใช้ Resource ในหน่วยความจำของเครื่อง และเพิ่มประสิทธิภาพในการประมวลผลโดยเฉพาะด้าน AI เมื่อเทียบรุ่น H100 ที่ใช้ Hopper กับรุ่นก่อนอย่าง A100 ที่ใช้ Ampere การเทรน AI นั้นมีความเร็วมากกว่า 9 เท่า และความเร็วในการใช้งานเครื่องมือที่เกี่ยวกับ AI สูงกว่า 30 เท่า ซึ่งเหมาะที่จะนำมาเทรนโมเดล AI อย่าง Large Language Models (LLMs) ด้วยประสิทธิภาพที่สูงกว่า graphic card ที่ใช้ Architecture ก่อนหน้า

Image Source https://www.nvidia.com/en-us/data-center/tensor-cores/
Ada Lovelace Architecture
ในปี 2022 เช่นกัน ทาง Nvidia ไปเปิดตัว Graphic Card ที่ใช้ Ada Lovelace Architecture ซึ่งเป็น 4th Generation เหมือนกับ Hopper เช่นกัน แต่เน้นไปทางด้าน render โมเดลให้มีคุณภาพสูงด้วยการใช้ RT Core ที่พัฒนาขึ้นในรุ่นนี้ ซึ่งมีใช้ใน RTX4000 series ที่เป็นระดับการใช้งานทั่วไป หรือในระดับ Server หรือ Data Center อย่าง L40 สเปคโดยรวมของ L40 มี Memory Size และ Bandwidth ที่ต่ำกว่า H100 แต่มีการใช้พลังงานที่มีประสิทธิภาพมากกว่า

Image source https://www.nextplatform.com/2022/09/21/nvidias-lovelace-gpu-enters-the-datacenter-through-the-metaverse/
เนื่องด้วยการใช้งาน Graphic Card ระดับ Server/Data Center นี้มีราคาค่อนข้างสูง ใช้เวลาในการติดตั้ง และต้องการ Maintenance อยู่เสมอ จึงอาจไม่ตอบโจทย์ผู้ใช้บริการรายย่อยหรือ ถ้าใช้งานได้ไม่เต็มที่ ก็จะเกิด Cost ที่เสียไปโดยเปล่าประโยชน์ การมาของบริการแบบใหม่อย่าง GPU as a service จึงได้เกิดขึ้น
GPU as a Service (GPUaaS) คืออะไร
ในปัจจุบัน เราสามารถใช้งานการประมวลจาก GPU โดยที่ไม่ต้องติดตั้ง Graphic Card ได้จากผู้ให้บริการ ซึ่งบริการนี้ เรียกว่า GPUaaS ซึ่งเป็น Cloud-based Solution ที่เข้าถึงการใช้ GPU ตามการใช้งานจริง (On-demand) สามารถ scale ได้ตามความต้องการแบบ Real Time ซึ่งมีความคุ้มค่า สะดวก และไม่ต้อง Maintain ตลอดเวลา เมื่อเทียบกับการติดตั้ง Graphic Card เอง

Image Source https://yotta.com/blog-the-gpuaas-revolution-transforming-hpc-and-virtual-pro-workstations/
Use Case ของการใช้ GPUaaS
ตัวอย่าง Applications ของการใช้ GPUaaS ได้แก่
- การวิจัยทางวิทยาศาสตร์
สามารถนำมาช่วยในการจำลองงานวิจัยต่างๆ อย่างเช่น โมเดลของโมเลกุล การพยากรณ์อากาศ หรือปฏิกิริยาทางนิวเคลียร์ เป็นต้น
- การพัฒนาด้าน AI และ Machine learning (ML)
GPU เปรียบเสมือนหัวใจหลักของ AI และ ML ซึ่งขาดไม่ได้ในการเทรนโมเดลต่างๆ ทำ Deep learning, Natural Language Process หรือ Computer Vision
- การวิเคราะห์ทางการเงิน
สถาบันทางการเงินใช้บริการเพื่อการวิเคราะห์ความเสี่ยง ป้องกันมิจฉาชีพ และเป็นตัวช่วยในการ trade ซึ่งการใช้บริการนี้ ช่วยให้การวิเคราะห์โมเดลทางการเงินที่ซับซ้อนได้ ทำให้ตัดสินใจได้รวดเร็วและถูกต้อง
- อุตสาหกรรม Healthcare
ในอุตสาหกรรมนี้ GPUaaS ถูกใช้เพื่อการทำ Medical Image Analysis (เป็นการวิเคราะห์อาการหรือหาสาเหตุของโรคจากภาพที่ได้จากการตรวจร่างกายผ่านเครื่อง MRI, CT scan หรือจากเครื่อง X-ray) พัฒนาตัวยาใหม่ๆ หรือวิจัยลักษณะพันธุกรรมของมนุษย์ ซึ่ง GPUaaS ช่วยให้การวิจัยเป็นไปอย่างรวดเร็วหรือทำให้เกิดการสร้างนวัตกรรมใหม่ๆ ได้
- โมเดล 3D และ Animation
GPUaaS ช่วยในการสร้าง Animation หรือโมเดล 3D ที่มีความซับซ้อนและรายละเอียดมาก ได้แบบ Real Time โดยไม่ติดปัญหาใดๆ
- การตัดต่อวิดีโอ
GPUaaS ช่วยให้การตัดต่อวิดีโอมีประสิทธิภาพมากขึ้นด้วยการเพิ่ม Resolution ให้กับวิดีโอ หรือทำ Compositing (นำ visual effect อย่าง CGI มาใส่ใน frame เดียวกับวิดีโอที่ถ่ายได้จริง เป็นเทคนิคที่ภาพยนตร์จากค่ายใหญ่ๆ ใช้เพื่อให้ดูสมจริง) ได้อย่างต่อเนื่องด้วยประสิทธิภาพที่สามารถ scale ได้สูงของ GPUaaS
ข้อดีของการใช้ GPUaaS
การใช้ GPUaaS นั้นมีข้อดีหลายอย่าง เช่น
- ความคุ้มค่า: องค์กรที่ใช้บริการสามารถลดค่าใช้จ่ายต่างๆ จากการติดตั้ง Graphic Cards และการดูแลรักษา เมื่อใช้บริการ GPUaaS
- Scalability: สามารถปรับขนาดทรัพยากรขึ้นหรือลงได้ตามความต้องการของโครงการ เพื่อให้แน่ใจว่ามีประสิทธิภาพสูงสุดโดยไม่ต้องจัดเตรียมเกินความจำเป็น
- การเข้าถึงง่าย: ให้บริการเข้าถึง Resource ของ GPU ที่มีประสิทธิภาพสูงตลอด 24 ชั่วโมงจากทุกที่ที่มีการเชื่อมต่ออินเทอร์เน็ต ซึ่งช่วยในการทำงานแบบ Remote
- มีความปลอดภัยและเชื่อถือได้: ผู้ให้บริการที่น่าเชื่อถือ จะมีระบบความปลอดภัยและ Infrastructure ที่ดี มีการตรวจสอบอยู่ตลอดเวลา ทำให้มั่นใจได้เมื่อใช้บริการ
- เพิ่มประสิทธิภาพ: สามารถเพิ่มความเร็วในการประมวลผลทางด้าน AI, Simulation ของระบบต่างๆ และ Render โมเดลได้ดียิ่งขึ้น
ผู้ให้บริการ GPUaaS ที่มีความน่าเชื่อถือและไว้วางใจได้ในไทย อย่างเช่น VMware นั้น เราจะมาดูรายละเอียดกันว่ามีสิ่งที่น่าสนใจอะไรบ้าง
Deep Dive into VMware: Exploring VMware’s Role in Supporting GPUs and LLMs
GPU (Graphics Processing Unit) ที่ถูกออกแบบมาเพื่อประมวลผลกราฟิกในตอนแรก ได้พัฒนาจนกลายเป็นหัวใจสำคัญของการประมวลผล AI และ Machine Learning ในปัจจุบัน ด้วยความสามารถในการคำนวณแบบขนานจำนวนมาก ทำให้ GPU กลายเป็นทรัพยากรที่มีค่าแต่มีต้นทุนสูง
ด้วยเหตุนี้ แนวคิด GPU as a Service (GPUaaS) จึงเกิดขึ้นเพื่อให้องค์กรสามารถใช้ประโยชน์จาก GPU โดยไม่ต้องลงทุนในฮาร์ดแวร์ราคาสูง โดยเฉพาะอย่างยิ่งในยุคที่ Large Language Models (LLMs) กำลังเป็นที่ต้องการ การใช้ GPUaaS จึงเป็นทางเลือกที่คุ้มค่าสำหรับการพัฒนาและปรับแต่ง AI โมเดล
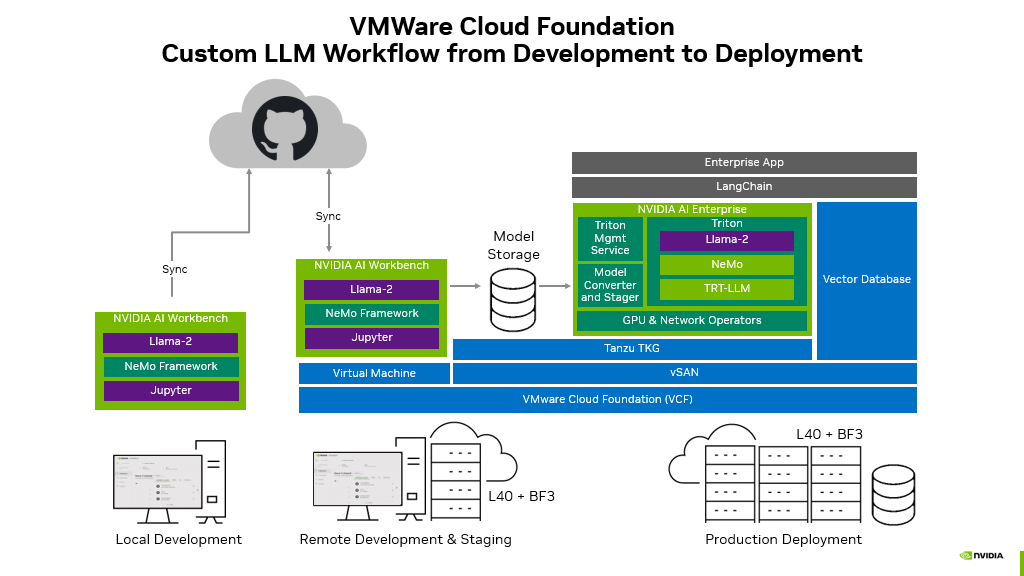
ในบริบทนี้ ทาง VMware ได้ร่วมมือกับ Nvidia ในการให้บริการ GPUaaS เพื่อยกระดับการใช้งาน AI ให้มีประสิทธิภาพสูงสุด ซึ่งบริการนี้ขื่อว่า VMware + NVIDIA AI-Ready Enterprise Platform เป็นการรวมกันของ Virtualization จาก VMware และเทคโนโลยีด้าน AI จาก Nvidia ซึ่งได้แก่
- NVIDIA AI Enterprise Suite
ส่วนนี้จะมี Tools และ Frameworks ที่จำเป็นในการสร้างโมเดล AI ยกตัวอย่างเช่น Pytorch, TRT-LLM หรือ NeMo
- VMware vSphere
ในส่วนของ Virtualization Platform นี้ คอยจัดการ Resource และ Deploy Virtual Machines (VMs) ที่ใช้งานในส่วนของ GPU resource
สามารถอ่านรายละเอียดเพิ่มเติมเรื่อง vSphere ได้จากบทความของทาง Cloud HM ที่นี่
- NVIDIA-Certified Systems
ระบบนี้จะใช้ Graphic Cards ที่มี Architecture ทั้งแบบ Ampere ไปจนถึง Hopper ขึ้นอยู่กับการออกแบบเพื่อการใช้งานที่เหมาะสม
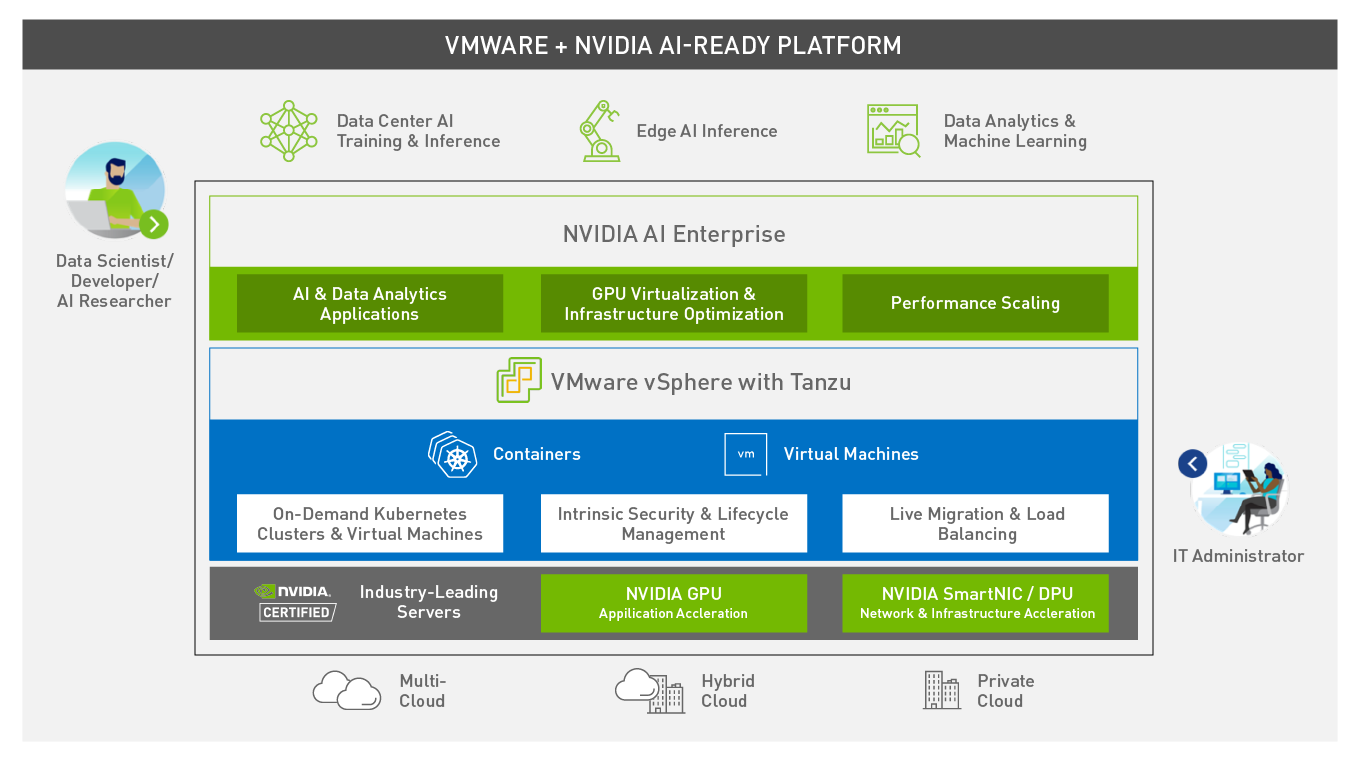
Image source https://blogs.nvidia.com/blog/vmware-ai-ready-enterprise-platform/
บริการนี้มีความสามารถในการทำได้หลากหลาย โดยเฉพาะการเทรน LLMs ซึ่งมีการใช้เทคโนโลยีอย่าง
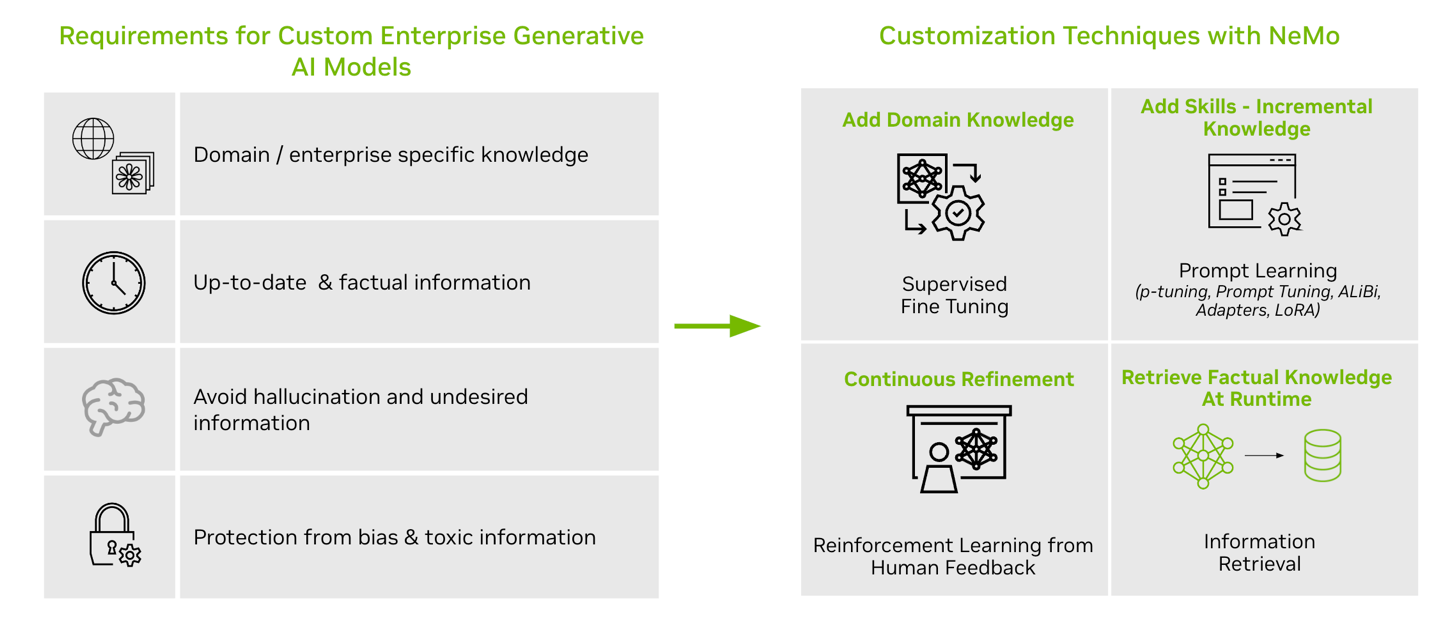
- NeMo Framework
เป็น Framework ที่ทำตั้งแต่ Build, Customize และ Deploy โมเดล AI ซึ่งสามารถปรับ LLMs ได้ด้วยการทำ P-tuning (หรือ Prompt Tuning เป็นเทคนิคที่ใช้โมเดลขนาดเล็กเพื่อทำการ Encode Prompt แล้วสร้าง Virtual Token ขึ้นมาและส่งไปยัง LLM เมื่อทำการ Tuning เสร็จแล้ว จะส่ง Virtual Token มาที่โมเดลขนาดเล็กนี้แล้วทำการเปลี่ยนค่า) หรือการทำ Reinforcement Learning (เป็น การเทรนแบบให้ตัดสินใจเลือกทางที่จะได้รางวัลหรือถูกใจผู้เทรนให้ได้มากที่สุดตามสถาณการณ์ที่กำหนดให้)
NeMo มีการ Integrate เข้ากับ NVIDIA Triton Inference Server เพื่อเพิ่มประสิทธิภาพในการทำ Inference Process (เป็นการนำโมเดลที่ถูกเทรนไปทดสอบกับข้อมูลใหม่ เพื่อตรวจสอบความแม่นยำในการหาคำตอบจากสิ่งที่ไม่เคยเทรน)
- TensorRT LLM หรือ (TRT-LLM)
หลักจากที่ LLM ถูก Tuning แล้วสามารถเพิ่มประสิทธิภาพได้ด้วยการใช้ Tool นี้เพื่อให้มี Latency ต่ำ และได้ Inference Throughput สูง
วิธีการทำงานคือ:
- ใช้ Python API ในการ compile TRT-LLM ลงบน GPU
- ใช้ภาษา Python และ C++ ในการสร้างและรัน TRT-LLM
- ทำงานร่วมกับ NVIDIA Triton Inference Server ที่ช่วยให้ใช้งานแบบออนไลน์ได้
มาถึงตรงนี้ ผู้เขียนหวังว่าผู้อ่านทุกท่านจะได้รับความรู้เกี่ยวกับเทคโนโลยีต่างๆ และการทำงานของ GPU รวมถึงเข้าใจการทำงานของ GPUaaS ไม่มากก็น้อย หากทางผู้อ่านท่านใดสนใจอยากทดลองใช้บริการ GPUaaS ในไทยที่มีความน่าเชื่อถือ ไว้วางใจได้ ท่านสามารถติดต่อทาง Cloud HM เพื่อขอรายละเอียดเพิ่มและทดลองใช้บริการนี้ เพื่อทำให้การทำงานของท่านมีประสิทธิภาพยิ่งขึ้นไป ขณะนี้ Cloud HM พร้อมให้บริการ Nvidia GPU as a Service สำหรับ LLMs บน VMware หากองค์กรของท่านต้องการปรึกษาผู้เชี่ยวชาญ ติดต่อได้ที่ Cloud HM
References
https://www.intel.com/content/www/us/en/products/docs/processors/what-is-a-gpu.html
https://www.gigabyte.com/Glossary/cuda
https://www.Nvidia.com/en-us/about-Nvidia/corporate-timeline/
https://modal.com/gpu-glossary/device-hardware/cuda-core
https://www.techspot.com/article/2049-what-are-tensor-cores/
https://www.digitalocean.com/community/tutorials/understanding-tensor-cores
https://en.wikipedia.org/wiki/Turing_(microarchitecture)
https://developer.nvidia.com/discover/ray-tracing
https://en.wikipedia.org/wiki/Ada_Lovelace_(microarchitecture)
https://medium.com/@bijit211987/top-nvidia-gpus-for-llm-inference-8a5316184a10
https://www.techdogs.com/td-articles/curtain-raisers/heres-why-you-need-gpu-as-a-service-gpuaas
https://yotta.com/blog-the-gpuaas-revolution-transforming-hpc-and-virtual-pro-workstations/
https://www.vmware.com/docs/vmw-nvidia-and-vmware-solution-brief
https://blogs.nvidia.com/blog/vmware-ai-ready-enterprise-platform/
https://nvidianews.nvidia.com/news/vmware-and-nvidia-unlock-generative-ai-for-enterprises
https://docs.nvidia.com/certification-programs/nvidia-certified-systems/index.html
https://www.geeksforgeeks.org/what-is-reinforcement-learning/