 Blog Home
Blog Home
Credit: Intel IT Peer Network
“Exascale computing” แปลตรงตัวว่าการคำนวณในระดับเอกซะ (exa – เป็นพหุคูณในระดับ 1018) เป็นคำที่ใช้เรียกการคำนวณที่มีประสิทธิภาพมาก ๆ เมื่อเทียบกับระดับการคำนวณที่ซุปเปอร์คอมพิวเตอร์ในปัจจุบันสามารถทำได้ ซึ่งคำ ๆ นี้ไม่ใช่คำศัพท์ใหม่อะไร เป็นคำที่มีมานานแล้วในวงการคอมพิวเตอร์ แต่ว่าเริ่มกลับมาเป็น Talk of The Town อีกครั้งก็เพราะว่าตอนนี้ Exascale มันได้เกิดขึ้นจริง ๆ แล้ว จากการจัดอันดับของ TOP500 ซุปเปอร์คอมพิวเตอร์เครื่องแรกที่มีขุมพลังในการคำนวณระดับ Petascale (1015 FLOPS) เริ่มใช้งานในปี ค.ศ. 2008. หลังจากนั้นไม่ถึงปี ในงานประชุม Supercomputing Conference (งานประชุมของซุปเปอร์คอมพิวเตอร์ที่ใหญที่สุดในโลก) ประจำปี ค.ศ. 2009 ได้มีการเริ่มหารือกันเกี่ยวกับจัดตั้งโครงการ Exascale implementation (1018 FLOPS) อย่างไรก็ตามนับตั้งแต่การประชุม SC 2009 ก็ยังมีความยากลำบากในการสร้างเครื่องคอมพิวเตอร์ที่มีประสิทธิภาพในระดับ Exascale
ถ้าหากจะอธิบายโครงการ Exascale ให้ละเอียด จะต้องเท้าความไปถึงโครงการ Exascale Computing Project (ECP) ซึ่งถูกจัดตั้งขึ้นโดยกระทรวงพลังงานของสหรัฐอเมริกา จนกระทั่งปี ค.ศ. 2018 สหรัฐอเมริกาก็ได้พิสูจน์ให้เห็นว่าความพยายามที่ได้ทุ่มเทกันมาอย่างอย่างยาวนานเกือบสิบปีนั้นไม่ได้สูญเปล่า โดยได้มีการเปิดตัวซุปเปอร์คอมพิวเตอร์เครื่องใหม่ในชื่อว่า Summit หรือ OLCF-4 supercomputer ซึ่งมีประสิทธิภาพในการคำนวณอยู่ที่ 1.8×1018 การคำนวณต่อวินาที (calculations per second) และหลังจากนั้นอีกไม่นานกำแพงที่กั้นเรากับ ExaFLOPS ได้ถูกทำลายลงอีกครั้งจากโครงการ Folding@home ซึ่งมีวัตถุประสงค์คือการสร้างโครงข่าย distributed supercomputer จากคอมพิวเตอร์ทั่วโลกผ่านระบบ network แบบพิเศษ
ผู้อ่านอาจจะตั้งคำถามว่าทำไมเราต้องการ Exascale supercomputer ทั้ง ๆ ที่เราก็มีซุปเปอร์คอมพิวเตอร์ระดับ Petascale อยู่แล้ว คำตอบก็คือจริง ๆ แล้วยังมีโจทย์ปัญหาหรือระบบที่ซับซ้อนที่ต้องใช้ระยะเวลาในการแก้เพื่อหาคำตอบหรือทำนายผล ซึ่ง Exascale ก็เข้ามามีบทบาทในจุดนี้ เช่น
- ช่วยให้เราสามารถประมวลผลข้อมูลที่มีขนาดใหญ่มาก ๆ ให้เสร็จได้ภายในเวลาไม่กี่นาที/ชั่วโมง จากปกติที่ต้องใช้เวลาหลายวัน
- ช่วยเร่งการประมวลแบบจำลองภัยพิบัติธรรมชาติ เช่น เส้นทางที่พายุเฮอริเคนจะเคลื่อนที่ไป หรือทำนายการเกิดแผ่นดินไหวล่วงหน้า ซึ่งจะช่วยชีวิตคนได้อีกนับไม่ถ้วน
- ช่วยจำลองหรือหาโครงสร้างของวัสดุทางเคมีชนิดใหม่ ๆ รวมไปถึงการออกแบบตัวยาอีกด้วย
- ทำนายการแพร่กระจายของไวรัสชนิดใหม่ ๆ ที่อาจจะมีการแพร่ระบาดอีกในอนาคต
- ทำนายสภาพเศรษฐกิจและวิเคราะห์ตัวแปรทางการเงิน รวมถึงปัจจัยที่สำคัญหลาย ๆ ปัจจัยพร้อมกันได้
จากตัวอย่างด้านบนที่ยกมานั้นจะเห็นว่าการลงทุนให้กับ Exascale แทบจะเล็กน้อยไปเลยเมื่อเทียบกับประโยชน์ที่มวลมนุษยชาติได้กลับคืนมา

Fugaku Supercomputer ประเทศญี่ปุ่น
Credit: CBS News
นอกเหนือจากสหรัฐอเมริกาแล้วยังมีประเทศมหาอำนาจอีกหลายประเทศที่ต่างก็อยากจะเข้ามามีบทบาทในการเป็นผู้นำทางด้านเทคโนโลยีในครั้งนี้ด้วย เช่น ประเทศจีนที่เคยมีซุปเปอร์คอมพิวเตอร์เบอร์หนึ่งของโลกก่อนที่จะโดน Summit โค่นลง และล่าสุดนั้น Fugaku ซุปเปอร์คอมพิวเตอร์สัญชาติญี่ปุ่นก็ผงาดขึ้นมาเป็นอันดับหนึ่งแทน Summit ไปเป็นที่เรียบร้อย โดย Fugaku มีประสิทธิมากขึ้น 442 PFLOPS และหลังจากนี้ก็เป็นที่น่าจับตามองว่าประเทศใดจะสามารถสร้าง Supercomputer ระดับ Exascale ออกมาได้ก่อนกัน
แล้วผู้อ่านเคยสงสัยกันไหมว่าเราวัดประสิทธิภาพการคำนวณของซุปเปอร์คอมพิวเตอร์ยังไง (จริง ๆ ขอแค่เป็นอุปกรณ์อิเล็กทรอนิกส์อะไรก็ได้ที่ใช้ processor ในการประมวลผล เช่น โทรศัพท์หรือแล็ปท็อปของเรา) แน่นอนว่าเราต้องวัดออกมาเป็นตัวเลขเพื่อที่เราจะสามารถนำตัวเลขมาเปรียบเทียบประสิทธิภาพหรือ “ความแรง” ของซุปเปอร์คอมพิวเตอร์แต่ละเครื่องได้ โดยสิ่งที่เราวัดออกมานั้นจะใช้ค่าเทียบเคียงที่เป็นการดำเนินการจุดทศนิยมต่อหนึ่งหน่วยวินาทีหรือ Floating point operations per second (FLOPS) ซึ่งค่า FLOPS นี้เป็นการวัดประสิทธิภาพมาตรฐานที่ใช้โดยรายการซูเปอร์คอมพิวเตอร์ TOP500 (https://www.top500.org) โดยจะจัดอันดับคอมพิวเตอร์ตามการดำเนินการ 64 บิต (รูปแบบจุดทศนิยมแบบ double-precision) ต่อวินาทีโดยใช้ library ที่ชื่อว่า HPL (High Performance LINPACK) ซึ่งพัฒนาโดยกลุ่มวิจัยของศาสตราจารย์ Jack Dongarra ที่ University of Tennessee, Knoxville โดยแต่ละปี TOP500 จะมีการจัดอันดับซุปเปอร์คอมพิวเตอร์ตามความสามารถในการประมวลผล 2 ครั้ง
สำหรับค่า FLOPS ก็มีการแบ่งตามเลข prefix ที่มีความต่างยกกำลังระดับ 1000 เท่า ตัวอย่างเช่น
- GigaFLOPS = 109 operations per second
- TeraFLOPS = 1012 operations per second
- PetaFLOPS = 1015 operations per second
- ExaFLOPS = 1018 operations per second
โดยค่า FLOPS สามารถคำนวณได้โดยใช้สมการต่อไปนี้ (สำหรับค่า GigaFLOPS)
Performance in GFlops = A x B x C x D
โดยตัวแปรแต่ละตัวคือ
A = CPU speed in GHz หรือ ความเร็วของ CPU ในหน่วย GHz
B = Number of CPU cores หรือ จำนวน CPU cores
C = CPU instruction per cycle หรือ ค่า instruction ของ CPU ต่อรอบ
D = Number of CPUs per node หรือ จำนวน CPU ต่อหนึ่งหน่วยประมวลผล
ตัวอย่างด้านล่างคือการใช้ HPL ในการคำนวณค่า GFlops ของคอมพิวเตอร์ของผู้เขียนที่ใช้หน่วยประมวลผล Intel Xeon
เครื่องที่ใช้ในการทดสอบครั้งนี้มี specfification คร่าว ๆ ตามนี้
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 24
On-line CPU(s) list: 0-23
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 63
Stepping: 2
CPU MHz: 2400.221
BogoMIPS: 4799.29
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 15360K
NUMA node0 CPU(s): 0,2,4,6,8,10,12,14,16,18,20,22
NUMA node1 CPU(s): 1,3,5,7,9,11,13,15,17,19,21,23
โดยหน่วยประมวล (computing node) เครื่องนี้มี 24 CPUs และมีหน่วยความจำ 32 GB
ถ้าหากผู้เขียนต้องการที่จะวัดประสิทธิภาพความแรงของพิมเตอร์เครื่องนี้ล่ะ จะทำยังไง ? ตามที่บอกไปก่อนหน้านี้ว่าเราสามารถใช้ HPL มาวัดค่า FLOPS ได้ โดยด้านล่างแสดงตัวอย่างผลลัพธ์ (output) ที่ได้ (ผู้เขียนขออนุญาตละขั้นตอนการใช้ HPL และการคำนวณแบบละเอียดไป ถ้าหากผู้อ่านสนใจก็สามารถหลังไมค์ติดต่อเข้ามาสอบถามได้)
CPU frequency: 3.199 GHz
Number of CPUs: 2
Number of cores: 12
Number of threads: 12
Parameters are set to:
Number of tests: 15
Number of equations to solve (problem size) : 1000 2000 5000 10000 15000 18000 20000 22000 25000 26000 27000 30000 35000 40000 45000
Leading dimension of array : 1000 2000 5008 10000 15000 18008 20016 22008 25000 26000 27000 30000 35000 40000 45000
Number of trials to run : 4 2 2 2 2 2 2 2 2 2 1 1 1 1 1
Data alignment value (in Kbytes) : 4 4 4 4 4 4 4 4 4 4 4 1 1 1 1
Maximum memory requested that can be used=16200901024, at the size=45000
=================== Timing linear equation system solver ===================
Size LDA Align. Time(s) GFlops Residual Residual(norm) Check
1000 1000 4 0.024 27.2993 9.394430e-13 3.203742e-02 pass
1000 1000 4 0.006 107.6577 9.394430e-13 3.203742e-02 pass
…
content skipped
…
35000 35000 1 99.141 288.3358 1.275258e-09 3.701880e-02 pass
40000 40000 1 146.370 291.5210 1.516881e-09 3.373595e-02 pass
45000 45000 1 213.964 283.9451 2.008430e-09 3.533621e-02 pass
Performance Summary (GFlops)
Size LDA Align. Average Maximal
1000 1000 4 86.9113 107.6577
…
content skipped
…
40000 40000 1 291.5210 291.5210
45000 45000 1 283.9451 283.9451
จาก output ของ HPL ด้านบนบอกอะไรเราบ้าง จริง ๆ ก็บอกหลายอย่าง แต่โดยสรุปแล้วคือในส่วนท้ายมีการบอกค่า GigaFLOPS ของเครื่อง Intel Xeon node ของผู้เขียนว่ามีประสิทธิภาพอยู่ที่ 283.945 GFlop/s จะเห็นได้ว่าเมื่อเรามีการใช้ FLOPS มาเป็นค่าวัด “ความแรง” ของคอมพิวเตอร์แล้ว นอกจากนี้เราก็ไม่ต้องมานั่งถกเถียงกันว่าคอมพิวเตอร์ของใครแรงกว่ากันอีกต่อไป เพราะว่าค่า FLOPS นี้เป็นค่ามาตรฐานที่ทุกคนต่างยอมรับ สรุปง่าย ๆ คือยิ่งมีค่า FLOPS เยอะยิ่งดี (เพราะฉะนั้นถ้าหากจะซื้อคอมพิวเตอร์เครื่องใหม่ก็ให้ถามพนักงานขายเลยนะว่ากี่ FLOPS อิอิ)
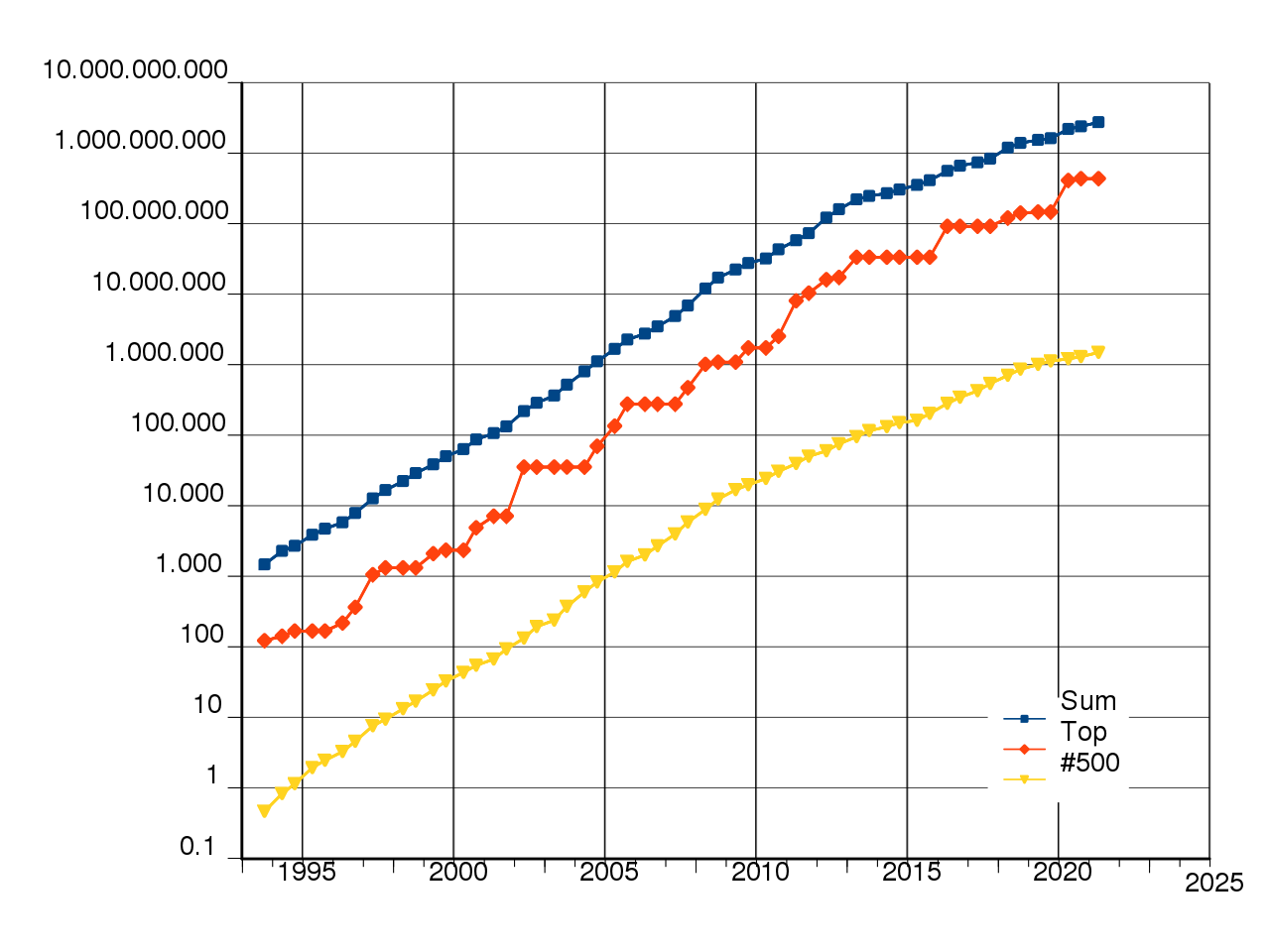
อัตราการเพิ่มขึ้นของประสิทภาพของซุปเปอร์คอมพิวเตอร์
Credit: wikipedia.org/wiki/TOP500
สำหรับผู้อ่านนั้นถึงแม้ว่าการประมวลผลในระดับ Petascale หรือ Exascale ไม่มีความจำเป็นต่องานหรือธุรกิจ แต่ว่าสิ่งที่เราได้เรียนรู้ก็คือถ้าหากว่าเราสามารถเปรียบเทียบประสิทธิภาพคอมพิวเตอร์หรือคลัยเตอร์ของเรากับซุปเปอร์คอมพิวเตอร์มาตรฐานที่มีพลังในการประทวลระดับโลกได้แล้ว เราจะสามารถคำนวณถึงจุดคุ้มทุนและความเหมาะสมในการปรับปรุง Platform ของเราได้เพื่อที่จะสามารถทำให้ธุรกิจของเราดำเนินไปได้โดยมีข้อด้อยน้อยที่สุด สำหรับระบบการประมวลผลแบบคลาวด์นั้น โดยเฉพาะการบริการของ AWS ที่มีระบบที่อำนวยความสะดวกให้ผู้ใช้งานสามารถปรับแต่งแก้ไขได้อย่างอิสระ จะช่วยให้เรา build ระบบคลาวด์ที่มีประสิทธิที่ยอดเยี่ยมได้อย่างแน่นอน นอกจากนี้เราอาจจะยังใช้ FLOPS มาเป็นตัวบอกประสิทธิภาพของระบบคลาวด์ของเราได้อีกด้วย
อ่านมาจนถึงจุดนี้แล้วถ้าหากผู้อ่านมีความสนใจในบริการของ AWS สามารถติดต่อ Cloud HM ได้โดยตรงเลย เพราะเรามีการให้บริการ Cloud Platform ครบวงจร ทั้ง Domestic Cloud และ Global Cloud เพื่อตอบสนองความต้องการรอบด้านของลูกค้าครับ
— Cloud HM