 Blog Home
Blog Home
สำหรับใครที่ทำงานสายเทค ไม่ว่าจะเป็น Data Engineers, Data Architects, Backend Developers หรือ DevOps Engineers เคยเจอปัญหานี้กันบ้างมั้ยครับ?
“ข้อมูลที่มีอยู่มันเยอะเกินไป!” เรียกได้ว่ามหาศาลเลยทีกว่าได้ ซึ่งข้อมูลเหล่านี้ก็เกิดจากแต่ละระบบที่สร้างขึ้นตลอดเวลา ไม่ว่าจะเป็น Log Files จาก Web Server ข้อมูลที่เราคอยติดตามผู้ใช้ผ่านการคลิกต่าง ๆ บนหน้าเว็บ รวมไปถึงข้อมูลที่ไหลเข้ามาเรื่อยจากอุปกรณ์ต่าง ๆ ในระบบ IoT นับพันชิ้นแล้ว ทั้งหมดนี้ถูกเก็บไว้ใน Amazon S3 แบบดิบ ๆ ที่ไม่ได้มีโครงสร้างที่ชัดเจน แล้วคำถามที่ตามมาคือ…
“เราจะจัดการกับข้อมูลมหาศาลพวกนี้ยังไง? จะวิเคราะห์มันให้เป็นประโยชน์ได้ยังไง โดยไม่ต้องไปสร้างระบบฐานข้อมูลให้ยุ่งยาก?”
วันนี้เราจะมาแนะนำให้รู้จักกับ “Amazon Athena” บริการที่สุดทรงพลังจาก AWS ที่เราสามารถคิวรีข้อมูลขนาดใหญ่ด้วย SQL จาก S3 ได้เลย แถมยังไม่ต้องมาตั้งค่าจัดการเซิร์ฟเวอร์ ไม่ต้องมี Infrastructure ที่ซับซ้อน และที่สำคัญคือมันประหยัดต้นทุนมาก
มาทำความรู้จักกับ Amazon Athena
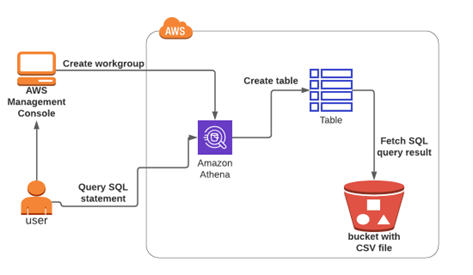
ที่มาของภาพ : https://towardsaws.com/introduction-to-amazon-athena-1080eab0bc7d
Amazon Athena เป็นบริการจาก AWS ที่ช่วยให้เราสามารถคิวรีข้อมูลที่อยู่ใน Amazon S3 ได้ โดยใช้เพียงแค่ภาษา SQL เท่านั้น ซึ่ง Amazon Athena เป็น
บริการแบบ Serverless หมายความว่า เราไม่ต้องสร้าง Server ไม่ต้องจัดการคลัสเตอร์ และไม่ต้องตั้งค่าใด ๆ เลย แค่เตรียมข้อมูลให้อยู่ใน S3 แล้วระบุว่าไฟล์นั้นมีโครงสร้างยังไงบ้าง เช่น CSV และ JSON เป็นต้น จากนั้นเราก็สามารถพิมพ์คำสั่ง SQL เพื่อเข้าถึงข้อมูลแล้วนำไปใช้ในการประมวลผลต่อได้ทันที
จุดเด่นหลักของ Amazon Athena
-
ไม่ต้องจัดการ Server เอง
เป็นหนึ่งในจุดแข็งที่สุดของ Amazon Athena คือความเป็น Serverless เต็มรูปแบบ โดยเราไม่จำเป็นต้องติดตั้งหรือจัดการเซิร์ฟเวอร์เอง ไม่ต้องเปิด EC2 ไม่มีคลัสเตอร์ ไม่ต้องมาสเกลเอง เทุกอย่างที่เกี่ยวกับ Infra ทาง Engineer ของ AWS จะดูแลให้หมด เราที่เป็นผู้ใช้ก็จะมีหน้าที่ “ใช้” ได้เลย
ซึ่งถ้าเทียบกับการที่เราต้องมาทำระบบเอง ลองนึกภาพว่าเราต้องตั้งระบบ Query ข้อมูลเองทั้งหมด เปิด EC2 ขึ้นมา ติดตั้งฐานข้อมูล ตั้งค่า Network กำหนด Scale คอยดูว่า CPU/RAM พอมั้ย แล้วต้องมีทีมคอย Monitor อีกว่าเซิร์ฟเวอร์ยังไม่ล่มหรือมีปัญหาอะไรหรือเปล่า บอกเลยว่าเหนื่อยครับ หากใช้ Amazon Athena คือ “เปิดมาปุ๊บ ยิง SQL ได้เลย” แล้วก็ได้ คำตอบจากข้อมูล หรือทำ Business Insight ไปใช้ต่อได้เลย
-
ใช้งานแค่ไหน จ่ายแค่นั้น
เป็น Concept หลักของ Serverless อยู่แล้วที่จะเป็นการคิดค่าบริการตามการใช้งานจริงโดยที่เราไม่ต้องจ่ายล่วงหน้า โดย Amazon Athena ก็เลยจะไม่มีการคิดค่าบริการรายเดือนหรือค่า Server จะคิดแค่ค่าบริการเมื่อเราคิวรีเท่านั้น โดยราคาจะขึ้นอยู่กับปริมาณข้อมูลที่ถูกสแกนตามความจริง
แอบบอกถ้าเราเราเขียนคิวรีที่ Filter ไว้ดี ๆ ข้อมูลที่ถูกสแกนก็จะน้อย ราคาที่ต้องจ่ายก็จะยิ่งถูกลงด้วย ยกตัวอย่างง่าย ๆ ถ้าเราเขียนคิวรีโดยใช้เงื่อนไข WHERE date = ‘2025-01-01’ โดยที่ไฟล์มี Partition แยกตามวัน Athena จะสแกนเฉพาะไฟล์ของวันนั้นเท่านั้นทำให้คิวรีได้เร็วและจ่ายเงินน้อยลงอีกด้วย
ซึ่งระบบทั่วไปเราต้องจ่ายค่าบริการแบบรายเดือน เช่น เปิด RDS หรือ Big Data Cluster ไว้ทั้งเดือนเพื่อให้คนในทีมเข้ามาคิวรีบ้างไม่คิวรีบ้าง บางทีก็แทบไม่ได้ใช้ แต่มันก็ยังคิดเงินเท่าเดิมอยู่ดี โมเดลการคิดเงินแบบ คิดเงินเฉพาะเวลาที่เรา “ยิงคิวรี” เท่านั้น ก็จะช่วยลดค่าใช้จ่ายลงไปได้อีกเยอะเลยครับ
-
เข้าถึงข้อมูลได้โดยตรง ไม่ต้องจัดการให้ยุ่งยาก
อีกจุดที่ทำให้ Amazon Athena โดดเด่นและแตกต่างจากเครื่องมือวิเคราะห์ข้อมูลแบบดั้งเดิมก็คือความสามารถในการ “เข้าถึงข้อมูลได้โดยตรงจาก S3” โดยไม่ต้องผ่านกระบวนการที่ซับซ้อนอย่างการโหลดข้อมูลลงเครื่อง หรือย้ายข้อมูลเข้าไปยังฐานข้อมูลก่อน โดยเมื่อก่อนเวลาเราจะวิเคราะห์ข้อมูลสักชุด เราก็จะต้องเตรียมหลายขั้นตอน ตั้งแต่ดึงข้อมูลออกมา แปลงรูปแบบให้เหมาะสม สร้าง schema ในฐานข้อมูล แล้วค่อยนำไปวิเคราะห์ แต่กับ Athena ทำให้เราลดกระบวนการจุกจิกเหล่านี้ไประดับนึง แค่เราต้องรู้ว่าข้อมูลที่ต้องการวิเคราะห์นั้นอยู่ที่ไหนใน S3 และมีโครงสร้างยังไง เราก็สามารถสร้างตารางขึ้นมาใน Athena แล้วใช้งานได้ทันที โดยการสร้างตารางใน Athena ไม่ได้หมายถึงการย้ายข้อมูลเข้าไปเก็บไว้ภายในระบบของ Athena แต่เป็นเพียงการอธิบายว่าไฟล์ข้อมูลมีโครงสร้างอย่างไร เช่น มีฟิลด์ชื่ออะไร แยกด้วยสัญลักษณ์อะไร และจัดเก็บไว้ที่ใดใน S3 เท่านั้นเอง
แต่ยังง่ายได้อีกคือ เราไม่จำเป็นต้องสร้าง schema เองตลอด เพราะเราสามารถใช้เครื่องมืออย่าง AWS Glue Crawler ให้ช่วยตรวจจับ schema ให้แบบอัตโนมัติ ทำให้ขั้นตอนทั้งหมดตั้งแต่การเตรียมข้อมูลไปจนถึงการเริ่มคิวรีใช้เวลาน้อยลงมาก และไม่ต้องอาศัยความรู้ด้านการจัดการระบบฐานข้อมูลแบบลึก ๆ อีกด้วย
-
รองรับข้อมูลหลายรูปแบบ
นอกจากที่เราได้พูดถึงไฟล์ CSV หรือ JSON ไปแล้ว จริง ๆ แล้ว Amazon Athena ยังรองรับข้อมูลในฟอร์แมตอื่น ๆ อีกเพียบ ไม่ว่าจะเป็น Parquet, Avro, ORC หรือแม้กระทั่งไฟล์ Log ที่มาจาก Apache Web Server หรือ CloudTrail โดยเราสามารถกำหนดให้อ่านข้อมูลผ่าน SerDe (Serializer/Deserializer) ที่เหมาะสมกับแต่ละรูปแบบได้ ซึ่งช่วยให้ Athena สามารถอ่านและคิวรีข้อมูลเหล่านี้ได้โดยตรง ๆ จาก Amazon S3 โดยไม่ต้องแปลงไฟล์หรือย้ายข้อมูล
-
เชื่อมต่อกับบริการอื่น ๆ ได้แบบ Seamless
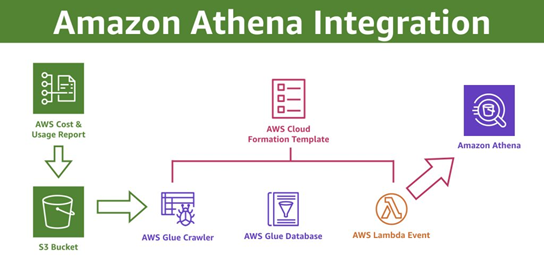
ที่มาของภาพ : Querying your AWS Cost and Usage Report using Amazon Athena | AWS Cloud Financial Management
พูดถึง Amazon Athena แล้ว ไม่ใช่แค่รัน SQL บนข้อมูลที่อยู่ใน S3 ได้เท่านั้น แต่จริง ๆ แมันสามารถเชื่อมต่อกับบริการอื่น ๆ ของ AWS ได้แบบง่ายมาก ช่วยให้เราทำ Solution ได้หลากหลายมากขึ้น โดยที่ไม่ต้องวุ่นวายกับการย้ายข้อมูลไปมา
ยกตัวอย่าง เช่น AWS Glue Data Catalog อันนี้เอาไว้เก็บข้อมูลพวก Schema หรือ Metadata ของไฟล์ใน S3 ซึ่ง Athena ก็สามารถเข้ามาใช้ข้อมูลจากตรงนี้ได้ทันที ไม่ต้องมาเสียเวลาสร้างใหม่เอง ทำให้จัดการข้อมูลได้เป็นระบบมากขึ้น ถ้าจะเอาข้อมูลไปทำ Dashboard สวย ๆ ก็มี Amazon QuickSight ที่เอาไว้สร้างกราฟหรือรายงานแบบ Interactive ได้เลย แค่ต่อ QuickSight เข้ากับ Athena ทุกอย่างก็แทบจะพร้อมใช้ทันที เหมาะกับคนที่อยากเห็นข้อมูลแบบเข้าใจง่าย ๆ
หรือใครที่ชอบระบบอัตโนมัติ ก็สามารถใช้ AWS Lambda มาช่วยได้ เช่น ตั้งให้ Lambda รันคิวรีจาก Athena แล้วเอาผลลัพธ์ไปใช้งานต่อโดยอัตโนมัติ ไม่ต้องมีคนมานั่งคลิกเอง ไม่ต้องมีเซิร์ฟเวอร์ให้วุ่นวาย ประหยัดทั้งเวลาและแรง เรื่องความปลอดภัยก็หายห่วง เพราะเราสามารถใช้ AWS CloudTrail เก็บ Log การใช้งานต่าง ๆ ไว้ใน S3 แล้วให้ Athena วิเคราะห์ข้อมูลพวกนี้ได้เลย เหมาะมากสำหรับการตรวจสอบย้อนหลังว่าใครทำอะไรไว้บ้าง
สุดท้ายถ้าใครมี Data Lake ที่เก็บข้อมูลไว้เยอะ ๆ ใน S3 แล้วอยากควบคุมว่าใครเข้าถึงอะไรได้บ้าง ก็มี AWS Lake Formation ที่ช่วยจัดการเรื่องสิทธิ์ให้เรียบร้อย แล้ว Athena ก็ยังสามารถเข้าถึงข้อมูลพวกนี้เพื่อวิเคราะห์ได้ตามสิทธิ์ที่กำหนดไว้เลย
มาดูความสำเร็จของการนำ Amazon Athena ไปใช้กันบ้าง

ที่มาของภาพ : https://www.youtube.com/watch?v=ZVK5sxxjxrk
ถ้าพูดถึงการเอา Amazon Athena ไปใช้แบบจริงจังในระดับโลก หนึ่งในตัวอย่างที่น่าสนใจมาก ๆ ก็คือ BMW Group แบรนด์รถยนต์หรูจากเยอรมนีที่หลายคนน่าจะรู้จักกันดี
เรื่องมันมีอยู่ว่า BMW เองก็ต้องจัดการกับข้อมูลจำนวนมหาศาลจากรถที่วิ่งอยู่บนถนนกว่า 1.2 ล้านคัน ทั่วโลก ข้อมูลพวกนี้ไม่ได้มาเล่น ๆ นะครับ มันเป็นพวกเซนเซอร์ที่อยู่ในรถ ข้อมูลการใช้งานต่าง ๆ ที่จะช่วยให้เขาพัฒนาบริการใหม่ ๆ ได้ แต่ปัญหาคือ ระบบเดิมที่เป็น on-premises data lake ของเขาเริ่มจะไม่ไหวแล้ว รับมือกับข้อมูลเยอะ ๆ ไม่ทัน แถมข้อมูลก็ถูกแยกเก็บไว้ตามที่ต่าง ๆ เป็นกอง ๆ ทำให้จะเอามาใช้วิเคราะห์อะไรก็ลำบากไปหมด
สิ่งที่ BMW ทำก็คือ ตัดสินใจย้ายระบบทั้งหมดขึ้น AWS Cloud แล้วสร้างสิ่งที่เรียกว่า Cloud Data Hub (CDH) ขึ้นมา ซึ่งเป็นเหมือนศูนย์รวมข้อมูลจากทุกแหล่ง ไม่ว่าจะเป็นจากรถ เซนเซอร์ต่าง ๆ หรือแหล่งอื่น ๆ แล้วเอามาผสานกันอย่างเป็นระบบ แถมยังเข้าถึงได้ง่ายขึ้นสำหรับทั้งทีมงานภายใน และระบบที่ต้องใช้ข้อมูลเพื่อให้บริการกับลูกค้าโดยตรง
ตรงนี้แหละครับที่ Amazon Athena โผล่มาเป็นพระเอก เพราะมันช่วยให้ทีมของ BMW สามารถรันคิวรีกับข้อมูลที่เก็บไว้ใน S3 ได้แบบไม่ต้องมีเซิร์ฟเวอร์ ไม่ต้องตั้งระบบให้ยุ่งยาก แถมยังสเกลได้ตามต้องการ จะใช้มากใช้น้อยก็ยืดหยุ่นได้เต็มที่
ผลลัพธ์ก็คือ ตอนนี้ BMW สามารถประมวลผลข้อมูลขนาดใหญ่ได้แบบสบาย ๆ ถึงวันละ 10 เทราไบต์ เลยทีเดียว! และข้อมูลพวกนี้ก็กลายมาเป็นพื้นฐานของบริการล้ำ ๆ อย่าง ผู้ช่วยส่วนตัวในรถที่สั่งงานด้วยเสียง หรือแม้แต่การวิเคราะห์ข้อมูลจากรถแบบ real-time เพื่อปรับปรุงประสบการณ์ของผู้ขับขี่และเพิ่มประสิทธิภาพการทำงานของระบบหลังบ้าน นอกจาก Athena แล้ว เขายังใช้บริการอื่น ๆ อย่าง Amazon Data Firehose, AWS Lambda และ Amazon SageMaker ร่วมกันด้วย เพื่อทำให้ระบบมันสมูท ครบเครื่อง และฉลาดขึ้นในทุกด้าน
มาดูอีกหนึ่งเคสเจ๋ง ๆ กันบ้าง คราวนี้เป็นของบริษัทที่ชื่อว่า Burt ซึ่งทำแพลตฟอร์มวิเคราะห์ข้อมูลสำหรับวงการสื่อและโฆษณาออนไลน์ ลูกค้าของเขาก็ระดับบิ๊ก ๆ ทั้งสำนักข่าวและบริษัทโฆษณาในยุโรปเหนือกับนิวยอร์กเลยทีเดียว
ย้อนกลับไปช่วงก่อนปี 2017 Burt เองก็เจอกับความท้าทายไม่เบา เพราะต้องจัดการข้อมูลจากแคมเปญโฆษณานับหมื่นรายการ แถมข้อมูลยังมากจากหลายแหล่งมาก ๆ ทำให้การรวบรวม วิเคราะห์ และสร้างรายงานแต่ละทีใช้เวลาไม่น้อยเลย ทีมก็เริ่มรู้สึกว่าระบบเดิมมันไม่ตอบโจทย์แล้ว
แล้วในที่สุด Burt ก็ตัดสินใจลองใช้ Amazon Athena ซึ่งจุดนี้เองทำให้ทีมของ Burt ทดลองโมเดลข้อมูลใหม่ ๆ ได้เร็วขึ้นเยอะ ไม่ต้องเสียเวลาตั้งระบบก่อนค่อยลอง เหมาะมากกับการทำงานแบบ Agile ที่เปลี่ยนโครงสร้างข้อมูลบ่อย ๆ ผลที่ได้คือ Burt สามารถลดเวลาการ onboard ลูกค้าใหม่ลงไปได้เกินครึ่ง จากเดิมที่ต้องเตรียมข้อมูลกันนาน ๆ ตอนนี้รวดเร็วและยืดหยุ่นมากขึ้น
อ่านมาถึงตรงนี้แล้ว เราจะเห็นได้เลยว่า Amazon Athena เป็นบริการที่จะช่วยให้เราดึงคำตอบ หรือ Business Insight ออกมาจากข้อมูลได้อย่างทันท่วงที ไม่จำเป็นต้องทำ ETL ที่วุ่นวาย ลดเรื่องการจัดการ Infrastructure โฟกัสกับการวิเคราะห์ข้อมูลได้อย่างเต็มที่ และหากคุณสนใจที่จะเริ่มต้นใช้งาน Amazon Athena หรือบริการอื่น ๆ ของ AWS เพื่อเพิ่มประสิทธิภาพในการจัดการและวิเคราะห์ข้อมูลขององค์กร ทางทีมผู้เชี่ยวชาญของ Cloud HM ของเราก็พร้อมจะให้คำปรึกษาและช่วยเหลือคุณ สนใจติดต่อเราได้ที่ https://www.cloudhm.co.th/th/contact-us
แหล่งอ้างอิง
Introduction to Amazon Athena
https://towardsaws.com/introduction-to-amazon-athena-1080eab0bc7d
Amazon Web Services. (n.d.). Creating Tables in Athena
https://docs.aws.amazon.com/athena/latest/ug/creating-tables.html
Amazon Web Services. (n.d.). Supported SerDes and data formats in Athena.
https://docs.aws.amazon.com/athena/latest/ug/supported-serdes.html
BMW Group at AWS re:Invent 2023
https://aws.amazon.com/solutions/case-studies/bmw-keynote-aws-reinvent-2023/
Amazon Web Services. “Burt: Seamless Adoption of Amazon Athena and AWS Glue.
https://aws.amazon.com/solutions/case-studies/burt-amazon-athena-and-aws-glue/